如何平稳的将 Elasticsearch 5.x 集群迁移到 Elasticsearch 7.x
背景⌗
公司的内容搜索业务主要基于 Elasticsearch 做的,老集群已经有五六年的历史,版本停留在了 5.6, 集群内的 document 数约有 20 亿的规模,磁盘占用不到 500 GB。
需要升级到新版本 es 的主要原因有以下几个:
- 前段时间偶发性的集群故障,导致崩溃,排查发现疑似版本 bug
- Elasticsearch 7.x 带来了一系列优化,包括性能有不小的提升
升级方案调研⌗
Rolling upgrades⌗
官方文档:rolling upgrades
由于旧集群版本为 5.x ,需要升级到的版本为 7.x,中间横跨两个大版本,根据 elastic 官方建议的升级 rolling upgrade 步骤,中间需要两次 rolling upgrade,分别为:
- From 5.x to 5.6
- From 5.6 to 6.8 (rolling upgrade)
- From 6.8 to 7.x (rolling upgrade)
升级过程中,还需要给集群设置一堆选项,这个过程看似很平滑,貌似可以做到 graceful shutdown,但是实际是不可逆的,中间任何一个步骤出错都很难立马恢复到升级前的状态。搜索服务需要高可用,而这些操作都是直接对线上集群进行操作,风险极大,一不小心可能会导致集群故障。因此这个升级方案不可行。
新集群 & 新索引⌗
除了对原集群 rolling upgrade,还有一种万无一失的升级方案,那就是直接开启一个 Elasticsearch 7.x 版本的新集群,集群 ready 之后,再把老的索引重建到新集群。一切准备好之后,还可以进行压测,对比性能、数据差异,并且全程不影响服务的可用性。具体升级流程如下:
- 搭建新集群,尽量保持配置与老集群一致。比如如果有 ik 插件,那么需要保证 ik 的词典文件与老集群一致
- 新建索引。这一步的目的是方便后面的索引能够同步双写到新老两个集群。同时建索引时需要注意,es7 已经废弃了 mapping 里的 document type,mapping 不再需要指定 type 了
- 索引双写。第二步已经将索引在新集群中建好了,这里在业务代码中开始双写,保证新增的 document 能够与老集群的索引一致
- 全量索引。新增索引一致后,存量的 document 也需要一致,因此需要把存量的 doc 重新全部导入到新集群内。这一步官方提供了一个 reindex from remote,但是实际操作后发现,reindex 后,mapping 和 settings 会有出入,并且不确定这个操作对老集群的压力大不大,因此还是决定跑下脚本人工重建
- 线上测试,包括性能测试、稳定性观察、数据比对等
- 停掉索引双写
- 下线老集群,全面覆盖新集群
测试新集群⌗
新集群准备好之后,需要进行一些必要的测试,比如:性能测试、数据比对、老的查询语句兼容性测试。
性能测试⌗
性能测试可以挑拣一个业务代码里最常用的查询语句,然后进行压测。比如我这里使用 wrk 压测一个最简单的全文搜索
// dsl.lua 文件内容
wrk.method = "GET"
wrk.body = [[{
"query":{
"match":{
"name":{
"query":"烘焙"
}
}
},
"size":100
}]]
wrk.headers["Content-Type"] = "application/json"
压测命令:
wrk -t10 -c10 -d10s --script=dsl.lua http://elasticsearch-address:9200/you_index/_search
结果示例:
Running 10s test @ http://elasticsearch-address:9200/you_index/_search
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 8.31ms 2.12ms 35.71ms 75.93%
Req/Sec 121.09 12.97 151.00 78.10%
12068 requests in 10.01s, 3.80GB read
Requests/sec: 1205.70
Transfer/sec: 388.64MB
可以适当调整压测参数,以及查询语句,通过比对 wrk 输出的 Avg latency 得出性能差异的结论。
数据比对⌗
与性能压测类似,找一些业务常用的查询语句,分别对两个集群查询结果采样,比对搜出来的结果是否有差异,依次判断索引是否有差异。
业务数据测试的同时,还需要测试插件加载是否与老集群一致,比如 ik 的词典文件是否正常加载,通常可以使用 /index/_analyze 接口来进行测试,并比对结果是否一致
诡异的毛刺⌗
在将索引迁移到新集群后,性能监控发现, 搜索请求经常性的出现毛刺,而且看起来是有规律的毛刺,如果 30s 内没有 search 请求,那么下一次必然会出现一根毛刺
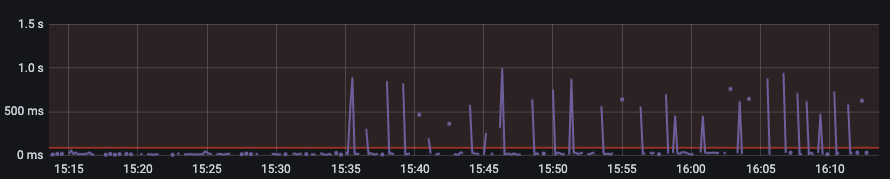
这个问题困扰了很久,排查思路如下:
-
首先查看是否为 SDK 的问题,是不是客户端到 es server 的长连接断了,导致 30s 后需要重新建立长连接,调长链接时间后发现并未改善
-
接下来看索引的
_stats信息,发现docs.deleted特别多。产生这么多 deleted 的原因可以解释,因为一个 update 操作等于一个 create + 一个 delete,创建新 doc,标记老 doc 为 deleted。但是在经过一段时间之后,merge 会把老的 segment 给合并掉,deleted 的 doc 也一并被清理了,但是这个指标却没有见变少,一直在增加,此时怀疑是 merge 流程的问题。是否 merge 未正常工作。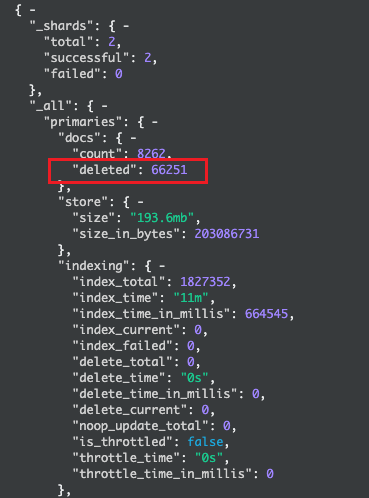
-
继续看索引的
_stats信息,发现refresh数非常奇怪,默认refresh_interval是 1s,也就是正常情况下是每秒刷新一次,refresh.total 也就是索引创建到当前时间的秒数,而几天前创建的索引,现在却只 refresh 了800+次,那么是否跟这个没有 refresh 有关系呢?为了验证这个问题,手动跑个脚本,在后台不间断的发送 search 请求,发现开始 refresh 了,毛刺也消失了,说明问题出在了 refresh 上面,出于某些原因没有正常的执行 refresh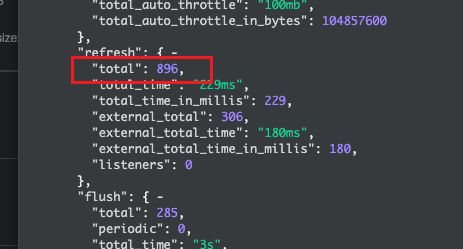
-
在一番查找之后,在 es 文档 的
refresh_interval字段解释里发现这么一句话,如果没有显示的指定refresh_interval,那么如果 30s 内没有 search 请求来,会跳过 refresh 步骤,直到有 search 请求来时,才会触发 refresh,并等 refresh 完之后才开始处理 search 请求。这也就能解释为什么 30s 没有搜索流量就会出现一根毛刺了。当手动给索引指定refresh_interval之后,默认行为就变得和老版本一样,不再跳过 refresh,毛刺也就消失了。在 elasticsearch 7.0 的 release note 里也提到了:

兼容性测试⌗
由于两个集群版本跨度比较大,容易出乌龙。比如下面这个 DSL,在 es 5.x 和 es7.x 两个版本的搜索结果迥然不同。
{
"query": {
"bool" : {
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
]
}
}
}
原因为:es5 bool query 只有 should 条件时,默认 minimum_should_match = 1,而到了 es7 里,默认值为 0 了,导致 es7 里搜出来的是全部 doc,而 es5 只会搜出符合条件的结果(default value of minimum should match。对于这些差异,可以事先阅读 breaking changes 7.0,并进行相应修改。对于有不兼容或者有差异的语句,在 数据比对 步骤也能够测出来。
后记⌗
在测试通过之后,就可以下线老集群,全面切换到新集群了🎉。
迁移过程中,有几个踩过的坑需要注意:
- es 7 已经废弃了 mapping type: Removal of mapping types
- 切词插件(ik) 结果比对,保证插件加载正常
- 关注新版本的一些默认值改动,一些 breaking changes